¡Descubre cómo crear un componente de tabla ordenable y filtrable en React, que te ayuda a agilizar tus procesos al t...
Dada la creciente amenaza de ataques cibernéticos, es crucial priorizar la seguridad de las API. Este resumen brinda ...
En este artículo de blog, exploramos la combinación de Akenza y Python para abrir nuevas oportunidades en integracion...
Electron ofrece flexibilidad al programador al permitirle mantener un único código JavaScript para crear aplicaciones...
La tarea de equilibrar las limitaciones de los dispositivos y las infraestructuras plantea desafíos, pero existe una ...
En el mundo en constante evolución del desarrollo de API, MuleSoft se posiciona como un jugador clave, ofreciendo un ...
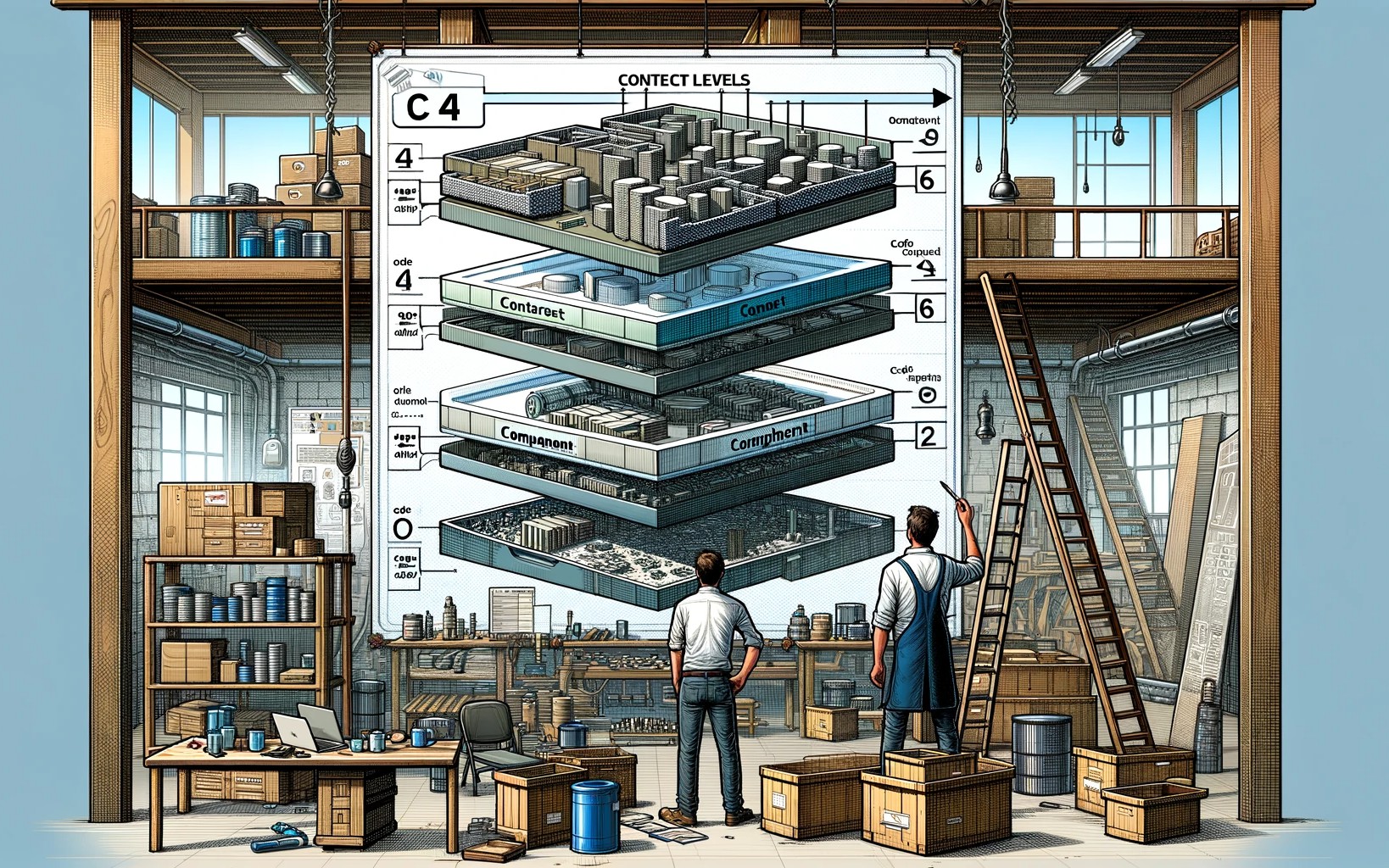
El Modelo C4 brinda un marco detallado para comprender y comunicar la arquitectura de software, equilibrando la compl...
Beneficia al cliente y optimiza las operaciones con una Interfaz de Usuario de Soporte bien elaborada, un activo fund...
DevSecOps es una metodología que puede ayudar a reducir errores al integrar pruebas de seguridad en cada etapa del de...
La Computación Edge y el Internet de las cosas se unen para lograr eficiencia en tiempo real, optimización de ancho d...
¡Descubre a través de un análisis basado en datos si POSIX es realmente inadecuado para almacenamientos de objetos! E...
Aprende las mejores estrategias para una implementación sin problemas de microservicios desde claras delimitaciones d...
En este artículo, nos adentraremos en las características, beneficios y casos de uso de Mesos, descubriendo cómo revo...
Este artículo de blog discutirá las tendencias más destacadas en el desarrollo de software que probablemente se convi...
El costo de cambiar o mantener el software es principalmente alto debido a la cascada, que es un cambio significativo...
Descubre cómo gestionar aplicaciones con estado utilizando StatefulSets de Kubernetes cómo usarlos, cómo implementar ...
Las técnicas de promoción facilitan el despliegue, permitiendo que los modelos se generalicen sin necesidad de datos ...
¡En esta guía, exploraremos todos los detalles de cómo utilizar la API de OpenAI ChatGPT con React JS, desbloqueando ...
Desplegar una aplicación en producción no es el fin, sino una etapa crucial en el ciclo de vida del desarrollo de sof...
Domina los contenedores Docker para un desarrollo web eficiente. Optimiza flujos de trabajo, adquiere un dominio en c...